Detección de Fraude Financiero
Prueba el Modelo
Introduce los datos de una transacción para predecir si es fraudulenta.
Metodología del Proyecto de Detección de Fraude
1. Configuración y Carga de Datos
El primer paso consiste en configurar el entorno de trabajo, importando librerías esenciales como pandas para la manipulación de datos, numpy para operaciones numéricas, y matplotlib y seaborn para visualización.
Se carga el conjunto de datos de transacciones financieras desde un archivo CSV a un DataFrame de Pandas para su posterior análisis.
import pandas as pd import numpy as np df = pd.read_csv('Financial_Fraud.csv') df.head()
2. Preprocesamiento y Feature Engineering
Se preparan los datos para el modelado. Las transacciones de
tipo CASH_IN no presentan fraude, por lo que se
pueden descartar para simplificar el modelo.
-
Codificación de variables: La variable
categórica
typese convierte a formato numérico mediante One-Hot Encoding. -
Creación de nuevas características: Se
diseñan variables como
hour(hora del día) yday(día de la semana) a partir de la columnasteppara capturar patrones temporales.
3. Análisis Exploratorio de Datos (EDA)
Se realiza un análisis profundo para entender la naturaleza de los datos. Esto incluye:
-
Análisis de la variable objetivo: Se
estudia la distribución de la variable
isFraudpara identificar el desbalance de clases, un problema común en la detección de fraude. - Correlación: Se analiza la relación entre las variables numéricas para detectar posibles multicolinealidades.
-
Distribución por tipo de transacción: Se
visualiza cómo se distribuyen las transacciones
fraudulentas y no fraudulentas entre los diferentes tipos
(
CASH_OUT,PAYMENT, etc.).
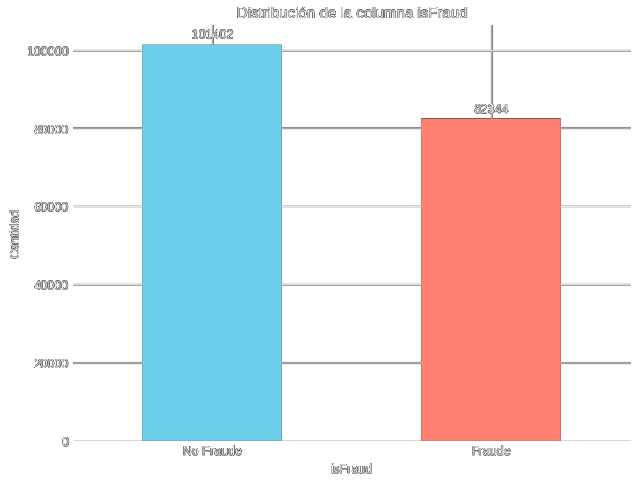
Visualización del balanceo de clases de fraude.
4. Modelado y Entrenamiento
Se seleccionan las características más relevantes y se dividen los datos en conjuntos de entrenamiento y prueba.
- Balanceo de datos: Dado el fuerte desbalance, se aplica la técnica SMOTE (Synthetic Minority Over-sampling Technique) al conjunto de entrenamiento para crear un set de datos balanceado.
- Entrenamiento de modelos: Se entrenan y comparan varios algoritmos de clasificación, como Regresión Logística y XGBoost, conocidos por su buen rendimiento en este tipo de problemas.
5. Evaluación y Conclusión
Los modelos se evalúan en el conjunto de prueba utilizando métricas clave para clasificación balanceada: Precision, Recall, F1-Score y la matriz de confusión.
El objetivo es maximizar el Recall (la capacidad de detectar fraudes reales) manteniendo una Precision aceptable para no generar demasiadas falsas alarmas.
Conclusión: El modelo XGBoost demostró un rendimiento superior, logrando un excelente equilibrio entre la detección de transacciones fraudulentas y la minimización de falsos positivos, convirtiéndolo en la elección final para la implementación.